Welcome to the second tutorial of the series Apache Airflow for beginners, in which we’ll be diving deep into the Apache Airflow Architecture. Make sure you haven’t missed the first part of series Introduction to Airflow, in which we talked about definition, why and when its needed and core terminologies like DAG, Tasks, task dependencies etc. Before we proceed further, familiarize yourself with the term workflow, which we will be using quiet often in this article. A Workflow is defined as sets of tasks arranged in specific order to deliver a specific business need. In Airflow terms, a workflow is a DAG consisting of tasks.
What you will Learn?
Today in the second part of our series we’re going to explore and understand the core components and the modular design of Apache Airflow Architecture. This Exploration will lead us to know, how the various components of Apache Airflow actually interact with each other. We’ll start of with a generic Airflow architecture proceeding with what type of executors Apache Airflow provides with the detailed architecture view of each of them.
By the end of this tutorial, you’ll know how airflow manages and executes workflow pipelines using single node architecture executors as well as multi-nodes. You’ll get a deep understanding of how each executor works, which is going to help you decide which one best suits your needs. So, let’s dive in.
Core Components
- Scheduler: As a workflow management platform, the core component that sits at the heart of airflow is a Scheduler. It is responsible for triggering the DAGs as well as the tasks according to their scheduled time and dependencies. It does that my monitoring tasks and kicking-off the downstream dependent tasks once the upstream tasks finish. To do so, Scheduler submits the tasks to an executor.
- Executor: An executor is a part of scheduler that handles and manages the running tasks. Airflow provides different types of executors, namely the major ones we’ll be looking at this tutorial are 2 single-node executors (local executor & Sequential executor) and 2 multi-node executors (Celery Executor & Kubernetes Executor).
- Worker: A place where the tasks run. This could be on the same machine/node where scheduler is running, if using single-node executors or a dedicated machine/node if using multi-node executors.
- Webserver: A user interface where users can view, control and monitor all DAGs. This interface provides functionality to trigger dag or a task manually, clear DAG runs, view task states & logs and view tasks run-duration. It also provides the ability to manage users, roles, and several other configurations for the Airflow setup.
- Metadata database: A database that stores workflow states, run duration, logs locations etc. This database also stores information regarding users, roles, connections, variables etc.
- Dags directory: A location where airflow stores all DAG codes. This is accessible to scheduler, webserver and workers.
- logs directory: A location where airflow store logs of all finished tasks. Location address of each task-run is stored in metadata database. User can then view the logs from this location via webserver UI. Airflow can also be configured to set remote log directory e.g. s3 or GCS.
How they work together ?
Lets now see how all of the above mentioned components work together. Diagram below illustrates an end-to-end process of how airflow runs a workflow. The workers section below is an illustration of a generic executor, whereas it will be different for different executors, we’ll be covering later in this article.
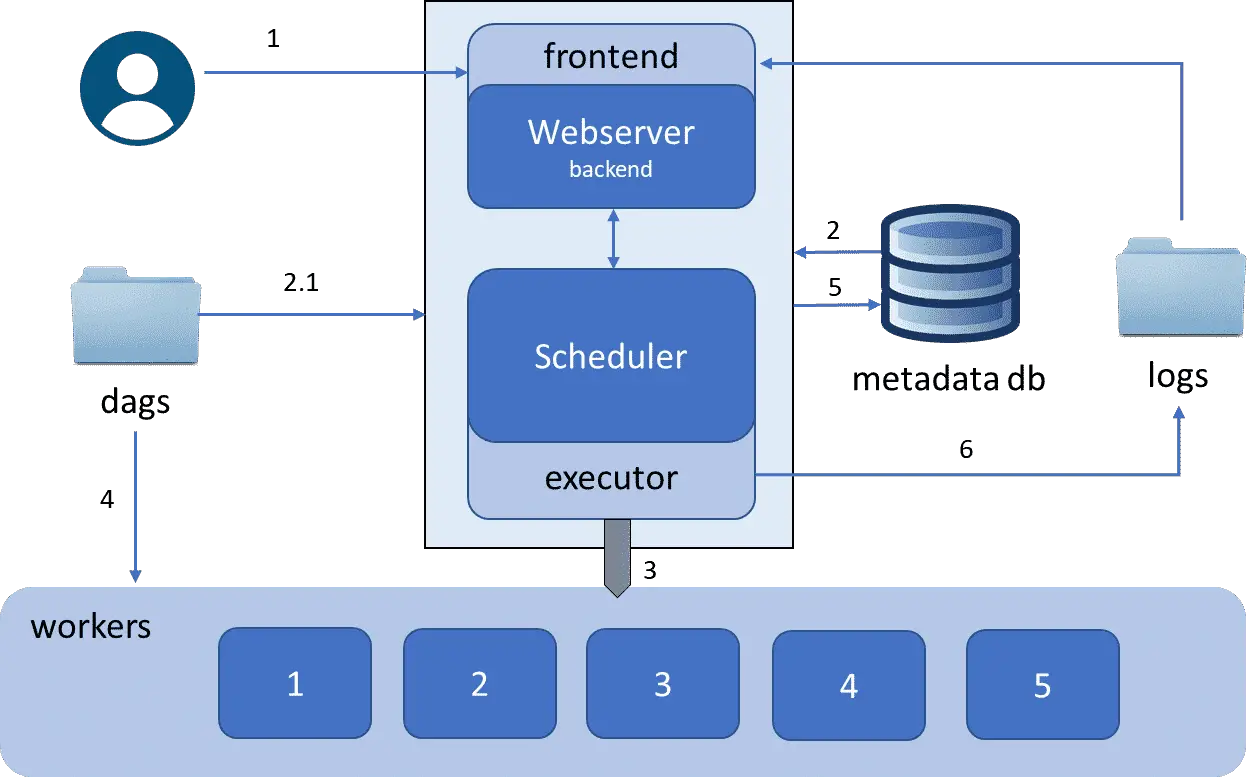
- A user first logins to the webserver interface to view and control workflows.
- Webserver then retrieves all dags from dags directory as well as pull information from metadata database about dag states.
- When a DAG gets triggered (whether automatically on its scheduled time or manually by user via webserver), a scheduler then submits the DAG tasks to executor. An Executor then submits these tasks to workers.
- A single worker takes care of one task at a time. For this, a worker fetches DAG code from dags directory and runs
- Upon tasks completion, executor retrieves tasks state from worker and updates into metadata database.
- Finally, executors fetches tasks logs from workers and persists them into logs directory, to be viewable from UI dashboard.
Executors Architecture
As discussed earlier, executor define a mechanism by which tasks get run. Airflow come with different type of executors. Lets look at the the high-level architecture of most famous airflow executors;
Sequential Executor
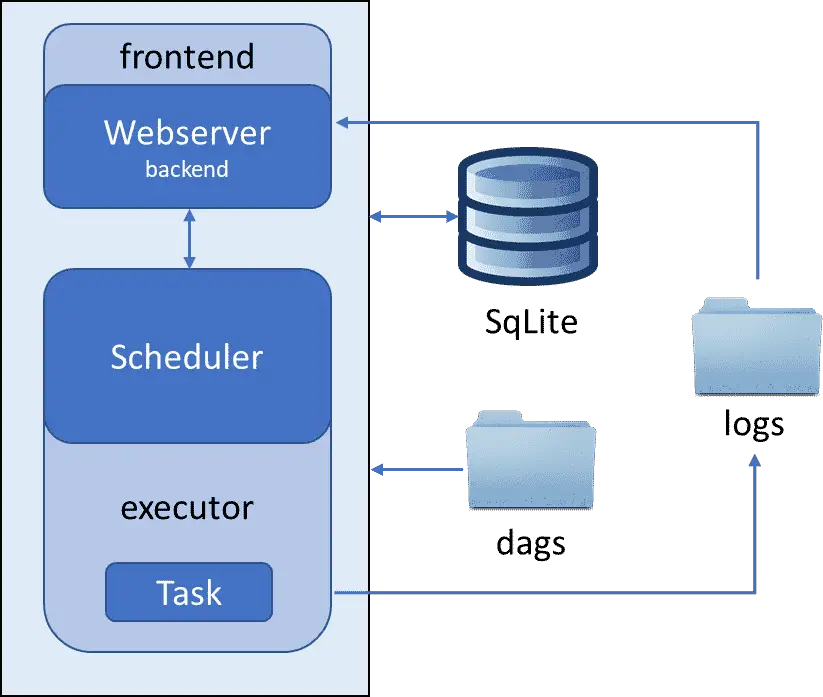
The simplest executor that is preconfigured as default with airflow. This executor runs the task within the same machine where scheduler is running as a new python sub-process. As the name says, this executor runs only one task instance at a time. because of its sequential nature, its the only executor what can run on SQLite database because this database supports only one connection at a time. Using any other database with this executor will be an overkill.
Pros
- No Setup Required: comes as default executor preconfigured with airflow
- Light Weight: no extra nodes required, all tasks run on scheduler node
- Cheap: due to its light weight
Cons
- Slow: runs one task at a time
- Not Scalable: because tasks run on same node where scheduler is running
- Single point of failure: Tasks fail if scheduler node dies
- Not Suitable for production: Because of all above
Local Executor
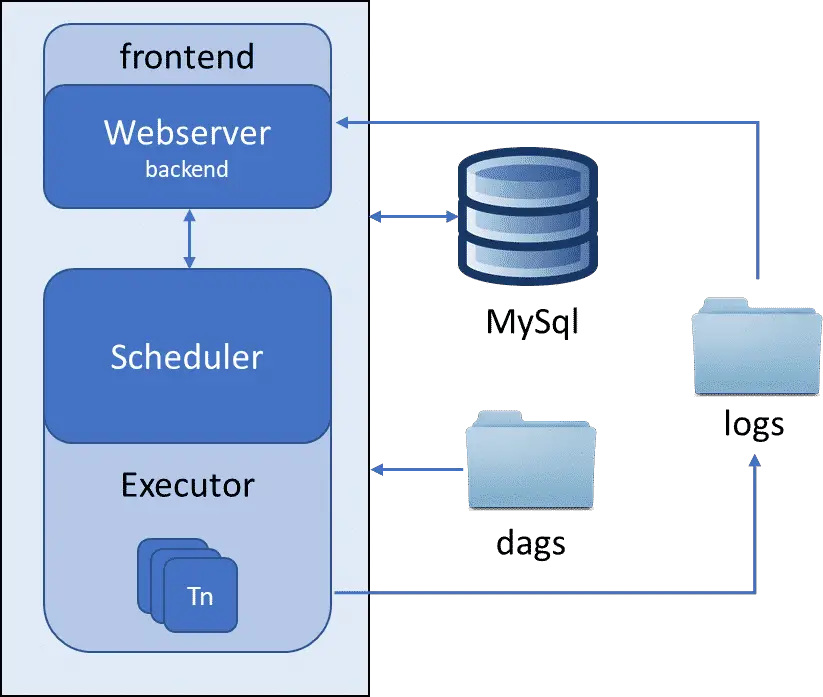
Local Executor is exactly the same as the sequential executor with the only difference being here is it can manage multiple task instances at a time by running multiple sub-processes within the same scheduler node. Because of its this nature, one can use any database other than SQLite for metadata storage. The two ideal ones are MySQL and PostgreSQL.
Pros:
- Easy to Setup: simply set environment variable AIRFLOW__CORE__EXECUTOR=LocalExecutor
- Cheap & Light Weight: Task instances run on same machine where scheduler is running, so no extra resources required
- Fast: Can run multiple tasks at a time
Cons:
- Single point of failure: Tasks fail if scheduler node dies
- Not suitable to scale: limited to scheduler node resources
- Not suitable for production: because of all above
Celery Executor
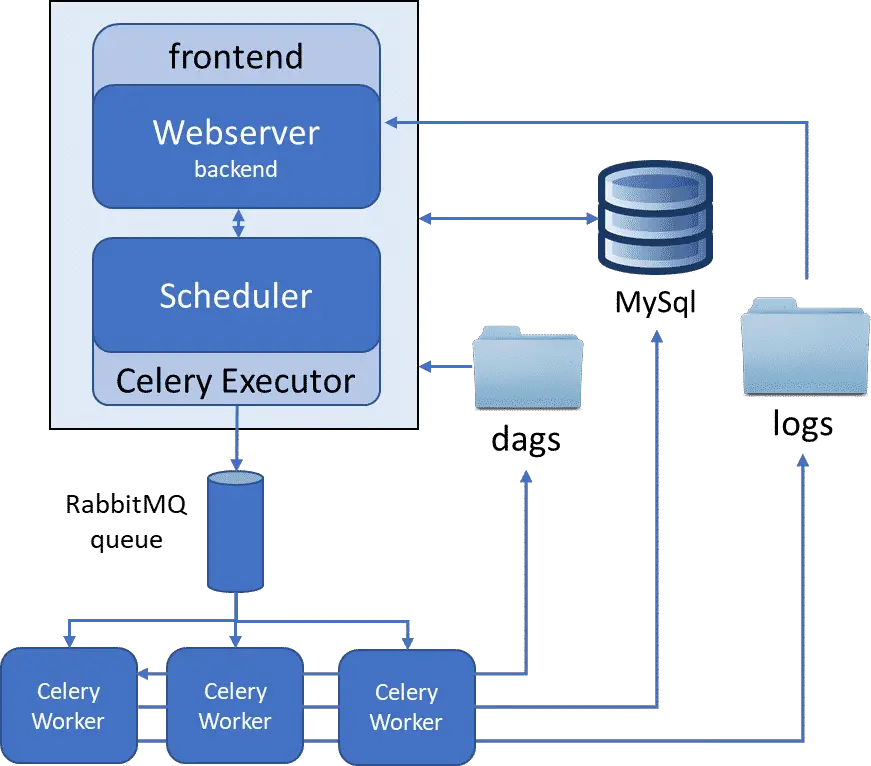
Celery executor unlike sequential and local executor runs the task on a dedicated machine. As the name says, it uses Celery distributed tasks queuing mechanism to perform tasks across fixed pool of workers. Airflow Scheduler adds the tasks into a queue and Celery broker then delivers them to the next available Celery worker, to be executed.
By default, a single Celery worker can run upto 16 tasks in parallel. You can limit this by setting environment variable AIRFLOW__CELERY__WORKER_CONCURRENCY. Note that the worker concurrency has upper-limit to dag_concurrency (number of task instances a scheduler is able to schedule at once per DAG).
Pros:
- Horizontally scalable: Set as many number of workers as required
- Fault tolerant: If a worker goes down, celery executor automatically assigns a task(s) to another healthy worker
- Production ready: due to all above
Cons:
- Relatively Complex setup: Additional resource setup required RabbbitMQ broker and workers
- Resource wastage if no task scheduled: Celery workers always running even if the task queue is empty
- Not cost effective: its pricier because of additional resources plus due to resource wastage.
Kubernetes Executor
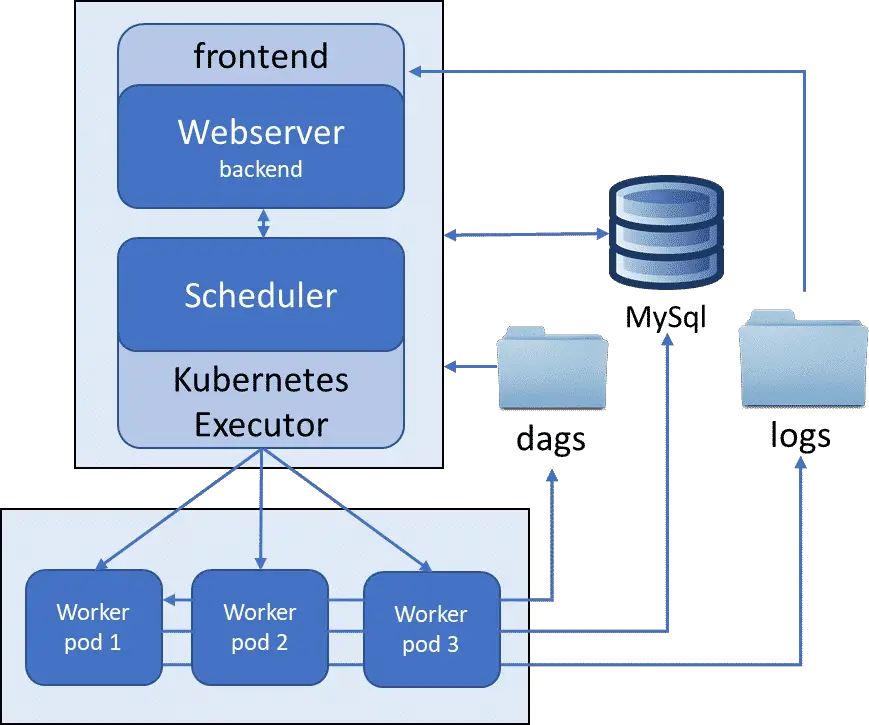
Kubernetes executer leverages the power of Kubernetes for resource management and optimization. It runs the tasks on a dedicated pod. A pod, in Kubernetes world, refers to a dedicated machine capable of running one or more container. This executor uses the Kubernetes API to dynamically launch pod for scheduled task, and monitors its state until it finishes. The task state and logs are then reported back to scheduler, stored in metadata database and made visible to view over the UI dashboard. Each pod can be assigned with different memory allocation according to the task requirements.
Pros:
- Can Scale down to zero: If no task(s) is scheduled, no worker pod will spin-up, whereas it can scale up to as many pods as required. So no resource wastage.
- Fault tolerant: Pods are re-spawned upon non-success termination
- Flexible resource allocation: Each task can individually be assigned its memory allocation, airflow image as well as service account.
- Cost & resource effective: Won’t be charged extra if no tasks(s) is scheduled
Cons:
- Pod launch time: A new worker pod spins-up upon new tasks execution. This adds few seconds of latency in workflow.
- Complex setup: Requires kubernetes knowledge, setting up cluster and executor configurations on top
Executors Comparison
Let us now compare all discussed executors and see which one is suitable for what kind of scenario. For this, lets break this comparison into two parts;
Single-node Executors
Local executor and Sequential executor falls under single node because the workers don’t require a dedicated machine. These executors are best for learning purpose. One can also test DAG workflow on these executors before deploying to production. Local executor is also been seen utilized as a replacement for less memory hungry light weight cron jobs. but you can’t really rely on single machine when number of cron jobs increase, as it starts to eat more memory and processing resources. These lightweight workflows in enterprises become complex over time, hence migration from local to remote (multi-node) executors is advised.
Multi-node Executors
To adopt production grade infrastructure, data engineers are normally seen migrating from single-node executors to multi-node. Especially because of their fault-tolerance and scalability nature. Out of these two remote executors, one would draw a comparison line based on following properties;
- Both are production ready
- Setup is not easy. Celery executor requires additional message broker setup, whereas Kubernetes executor requires you to have kubernetes knowledge to setup the cluster first.
- Celery executor has always running workers, whereas Kubernetes spins-up workers on-demand
- Celery executor defines fixed worker configuration for all tasks whereas each kuberenetes worker pod can be configured separately.
Based on the above properties, decide to use either of the remote-executor based on following scenarios;
- If an existing Local executor cannot bare the task load, and your workflow contains tasks scheduled 80% of the times, then celery executor can be a good fit. Because you are utilizing workers most of the time, which would other-wise sit idle and consume running cost.
- If you’re harshly concerned about not wasting any resources and only pay for what you use, I’d recommend to go for Kubernets executor. This would also be the case even when you don’t have knowledge about kubernetes. One time setup may take time, but this investment will save you allot.